Критическое значение фишера. Точный критерий фишера
Возвращает значение, обратное (правостороннему) F-распределению вероятностей. Если p = FРАСП(x;...), то FРАСПОБР(p;...) = x.
F-распределение может использоваться в F-тесте, который сравнивает степени разброса двух множеств данных. Например, можно проанализировать распределение доходов в США и Канаде, чтобы определить, похожи ли эти две страны по степени плотности доходов.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Чтобы узнать больше о новых функциях, см. статьи Функция F.ОБР и Функция F.ОБР.ПХ .
Синтаксис
FРАСПОБР(вероятность;степени_свободы1;степени_свободы2)
Аргументы функции FРАСПОБР описаны ниже.
Вероятность - обязательный аргумент. Вероятность, связанная с интегральным F-распределением.
Степени_свободы1 - обязательный аргумент. Числитель степеней свободы.
Степени_свободы2 - обязательный аргумент. Знаменатель степеней свободы.
Замечания
Если какой-либо из аргументов не является числом, функция FРАСПОБР возвращает значение ошибки #ЗНАЧ!.
Если "вероятность" < 0 или "вероятность" > 1, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!.
Если значение аргумента "степени_свободы1" или "степени_свободы2" не является целым числом, оно усекается.
Если "степени_свободы1" < 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!.
Если "степени_свободы2" < 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!.
Функцию FРАСПОБР можно использовать для определения критических значений F-распределения. Например, результаты дисперсионного анализа обычно включают данные для F-статистики, F-вероятности и критическое значение F-распределения с уровнем значимости 0,05. Чтобы определить критическое значение F, нужно использовать уровень значимости как аргумент "вероятность" функции FРАСПОБР.
По заданному значению вероятности функция FРАСПОБР ищет значение x, для которого FРАСП(x;степени_свободы1;степени_свободы2) = вероятность. Таким образом, точность функции FРАСПОБР зависит от точности FРАСП. Для поиска функция FРАСПОБР использует метод итераций. Если поиск не закончился после 100 итераций, возвращается значение ошибки #Н/Д.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем - клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
На данном примере рассмотрим, как оценивается надежность полученного уравнение регрессии. Этот же тест используется для проверки гипотезы о том, что коэффициенты регрессии одновременно равны нулю, a=0 , b=0 . Другими словами, суть расчетов - ответить на вопрос: можно ли его использовать для дальнейшего анализа и прогнозов?
Для установления сходства или различия дисперсий в двух выборках используйте данный t-критерий .
Итак, целью анализа является получение некоторой оценки, с помощью которой можно было бы утверждать, что при некотором уровне α полученное уравнение регрессии - статистически надежно. Для этого используется коэффициент детерминации R 2
.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k 1 =(m) и k 2 =(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H 0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
![]()
![]()
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2 (или через функцию Excel FРАСПОБР(вероятность;1;n-2)).
F табл - это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости α. Уровень значимости α - вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно α принимается равной 0,05 или 0,01.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k 1 =1 и k 2 =48, F табл = 4
Выводы : Поскольку фактическое значение F > F табл, то коэффициент детерминации статистически значим (найденная оценка уравнения регрессии статистически надежна ) .
Дисперсионный анализ
.Показатели качества уравнения регрессии
Пример
. По совокупности 25 предприятий торговли изучается зависимость между признаками: X - цена на товар А, тыс. руб.; Y - прибыль торгового предприятия, млн. руб. При оценке регрессионной модели были получены следующие промежуточные результаты: ∑(y i -y x) 2 = 46000; ∑(y i -y ср) 2 = 138000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину этого показателя, на основе этого результата и с помощью F-критерия Фишера
сделайте вывод о качестве модели регрессии.
Решение. По этим данным можно определить эмпирическое корреляционное отношение : 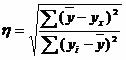 , где ∑(y ср -y x) 2 = ∑(y i -y ср) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
, где ∑(y ср -y x) 2 = ∑(y i -y ср) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
η 2 = 92 000/138000 = 0.67, η = 0.816 (0.7 < η < 0.9 - связь между X и Y высокая).
F-критерий Фишера
: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F табл (1; 23) = 4.27
Поскольку фактическое значение F > Fтабл, то найденная оценка уравнения регрессии статистически надежна.
Вопрос: Какую статистику используют для проверки значимости модели регрессии?
Ответ: Для значимости всей модели в целом используют F-статистику (критерий Фишера).
Функция ФИШЕР выполняет возвращение преобразования Фишера для аргументов X . Это преобразование строит функцию, которая имеет нормальное, а не асимметричное распределение. Используется функция ФИШЕР для того чтобы проверить гипотезу с помощью коэффициента корреляции.
Описание работы функции ФИШЕР в Excel
При работе с данной функцией необходимо задать значение переменной. Сразу стоит отметить, что существуют некоторые ситуации, при которых данная функция не будет выдавать результатов. Это возможно, если переменная:
- не является числом. В такой ситуации функция ФИШЕР осуществит возвращение значения ошибки #ЗНАЧ!;
- имеет значение либо меньше -1, либо больше 1. В данном случае функция ФИШЕР возвратит значение ошибки #ЧИСЛО!.
Уравнение, которое используется для математического описания функции ФИШЕР, имеет вид:
Z"=1/2*ln(1+x)/(1-x)
Рассмотрим применение данной функции на 3-x конкретных примерах.
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
- Рассчитывается линейный коэффициент корреляции r xy ;
- Проверяется значимость линейного коэффициента корреляции на основе t-критерия Стьюдента. При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю. При проверке этой гипотезы используется t-статистика. Если гипотеза подтверждается, t-статистика имеет распределение Стьюдента. Если расчетное значение t р > t кр, то гипотеза отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а следовательно, и о статистической существенности зависимости между Х и Y;
- Определяется интервальная оценка для статистически значимого линейного коэффициента корреляции.
- Определяется интервальная оценка для линейного коэффициента корреляции на основе обратного z-преобразования Фишера;
- Рассчитывается стандартная ошибка линейного коэффициента корреляции.
Результаты решения данной задачи с применяемыми функциями в пакете Excel приведены на рисунке 1.

Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Проверка статистической значимости регрессии по функции FРАСПОБР
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н 0 о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н 1 о статистической значимости коэффициента детерминации:
Н 1: R 2 ≠ 0.
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
Для этого используем в пакете Excel функцию:
FРАСПОБР (α;p;n-p-1)
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для F крит (см. рисунок 2).
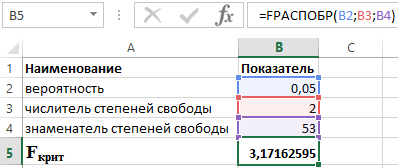
Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что F расч > F крит. В итоге принимается гипотеза Н 1 о статистической значимости коэффициента детерминации.
Расчет величины показателя корреляции в Excel
Пример 3. Используя данные 23 предприятий о: X - цена на товар А, тыс. руб.; Y - прибыль торгового предприятия, млн. руб, производится изучение их зависимости. Оценка регрессионной модели дала следующее: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину показателя корреляции и, используя критерий Фишера, сделайте вывод о качестве модели регрессии.
Определим F крит из выражения:
F расч = R 2 /23*(1-R 2)
где R – коэффициент детерминации, равный 0,67.
Таким образом, расчетное значение F расч = 46.
Для определения F крит используем распределение Фишера (см. рисунок 3).

Рисунок 3 – Пример расчетов.
Таким образом, полученная оценка уравнения регрессии надежна.
1. Таблица значений F-критерия Фишера для уровня значимости α = 0.05
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 12 | 24 | ∞ | |
| 1 | 161,45 | 199,50 | 215,72 | 224,57 | 230,17 | 233,97 | 238,89 | 243,91 | 249,04 | 254,32 |
| 2 | 18,51 | 19,00 | 19,16 | 19,25 | 19,30 | 19,33 | 19,37 | 19,41 | 19,45 | 19,50 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,84 | 8,74 | 8,64 | 8,53 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,04 | 5,91 | 5,77 | 5,63 |
| 5 | 6,61 | 5,79 | 5,41 | 5, 19 | 5,05 | 4,95 | 4,82 | 4,68 | 4,53 | 4,36 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,15 | 4,00 | 3,84 | 3,67 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,73 | 3,57 | 3,41 | 3,23 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,44 | 3,28 | 3,12 | 2,93 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,23 | 3,07 | 2,90 | 2,71 |
| 10 | 4,96 | 4,10 | 3,71 | 3,48 | 3,33 | 3,22 | 3,07 | 2,91 | 2,74 | 2,54 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3, 20 | 2,95 | 2,79 | 2,61 | 2,40 |
Когда m=1, выбираем 1 столбец.
k 2 =n-m=7-1=6 - т.е.6-я строка - берем табличное значение Фишера
F табл =5.99, у ср. = итого: 7
Влияние х на у - умеренное и отрицательное
ŷ - модельное значение.
| F расч. = | 28,648: 1 | = 0,92 |
| 200,50: 5 |
А = 1/7 * 398,15 * 100% = 8,1% < 10% -
приемлемое значение
Модель достаточно точная.
F расч. = 1/0,92 =1,6
F расч. = 1,6 < F табл. = 5,99
Должно быть F расч. > F табл
Нарушается данная модель, поэтому данное уравнение статистически не значимо.
Так как расчетное значение меньше табличного - незначимая модель.
| 1 | Σ | (y - ŷ) | *100% | |
| N | y |
Ошибка аппроксимации.
A= 1/7*0,563494* 100% = 8,04991% 8,0%
Считаем, что модель точная, если средняя ошибка аппроксимации менее 10%.
Параметрическая идентификация парной нелинейной регрессии
Модель у = а * х b - степенная функция
Чтобы применить известную формулу, необходимо логарифмировать нелинейную модель.
log у = log a + b log x
Y=C+b*X -линейная модель.
С = 1,7605 - (- 0,298) * 1,7370 = 2,278
Возврат к исходной модели
Ŷ=10 с *x b =10 2.278 *x -0.298
| №п/п | У | X | Y | X | Y*X | У | I (y-ŷ) /yI | |
| 1 | 68,80 | 45,10 | 1,8376 | 1,6542 | 3,039758 | 2,736378 | 60,9614643 | 0,113932 |
| 2 | 61, 20 | 59,00 | 1,7868 | 1,7709 | 3,164244 | 3,136087 | 56,2711901 | 0,080536 |
| 3 | 59,90 | 57, 20 | 1,7774 | 1,7574 | 3,123603 | 3,088455 | 56,7931534 | 0,051867 |
| 4 | 56,70 | 61,80 | 1,7536 | 1,7910 | 3,140698 | 3, 207681 | 55,4990353 | 0,021181 |
| 5 | 55,00 | 58,80 | 1,7404 | 1,7694 | 3,079464 | 3,130776 | 56,3281590 | 0,024148 |
| 6 | 54,30 | 47, 20 | 1,7348 | 1,6739 | 2,903882 | 2,801941 | 60,1402577 | 0,107555 |
| 7 | 49,30 | 55, 20 | 1,6928 | 1,7419 | 2,948688 | 3,034216 | 57,3987130 | 0,164274 |
| Итого | 405, 20 | 384,30 | 12,3234 | 12,1587 | 21,40034 | 21,13553 | 403,391973 | 0,563493 |
| Средняя | 57,88571 | 54,90 | 1,760486 | 1,736957 | 3,057191 | 3,019362 | 57,62742 | 0,080499 |
Входим в EXCEL через "Пуск"-программы. Заносим данные в таблицу. В "Сервис" - "Анализ данных" - "Регрессия" - ОК
Если в меню "Сервис" отсутствует строка "Анализ данных", то ее необходимо установить через "Сервис" - "Настройки" - "Пакет анализа данных"
Прогнозирование спроса на продукцию предприятия. Использование в MS Excel функции "Тенденция"
A - спрос на товар. B - время, дни
| № п/п | A | |
| 1 | 11 | 1 |
| 2 | 14 | 2 |
| 3 | 13 | 3 |
| 4 | 15 | 4 |
| 5 | 17 | 5 |
| 6 | 17,9 | |
| 7 | 18,4 | 7 |
Шаг 1. Подготовка исходных данных
Шаг 2. Продлеваем временную ось, ставим на 6,7 вперед; имеем право прогнозировать на 1/3 от данных.
Шаг 3. Выделим диапазон A6: A7 под будущий прогноз.
Шаг 4. Вставка функция
Вставка диаграмма нестандартны гладкие графики
диапазон у готово.

Если каждое последующее значение нашего временной оси будет отличаться не на несколько процентов, а в несколько раз, тогда нужно использовать не функцию "Тенденция", а функцию "Рост".
Список литературы
1. Елисеева "Эконометрика"
2. Елисеева "Практикум по эконометрике"
3. Карлсберг "Excel для цели анализа"
Приложение
| ВЫВОД ИТОГОВ | ||||||||
| Регистрационная статистика | ||||||||
| Множественный R | 0,947541801 | |||||||
| R-квадрат | 0,897835464 | |||||||
| Нормированный R-квадрат | 0,829725774 | |||||||
| Стандартная ошибка | 0,226013867 | |||||||
| Наблюдения | 6 | |||||||
| Дисперсионный анализ | ||||||||
| Значимость F | ||||||||
| Регрессия | 2 | 1,346753196 | 0,673376598 | 13,18219855 | 0,032655042 | |||
| Остаток | 3 | 0,153246804 | 0,051082268 | |||||
| Итого | 5 | 1,5 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | Р-значение | Нижние 95% | Верхние 95% | Нижние 95% | Верхние 95% |
|
| Y-пересечение | 4,736816539 | 0,651468195 | 7,27098664 | 0,005368842 | 2,66355399 | 6,810079088 | 2,66355399 | 6,810079088 |
| Переменная X1 | 0,333424008 | 0,220082134 | 1,51499807 | 0,227014505 | -0,366975566 | 1,033823582 | -0,366975566 | |





Назначение. Проверка гипотезы о принадлежности двух дисперсий одной генеральной совокупности и следовательно - их равенстве.
Нулевая гипотеза. S 2 2 = S 1 2
Альтернативная гипотеза . Существуют следующие варианты Н А в зависимости от которых различаются критические области:
1. S 1 2 > S 2 2 . Наиболее часто используемый вариант Н А. Критическая область - верхний хвост F-распределения.
2. S 1 2 < S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. Двухсторонняя S 1 2 ≠S 2 2 .Комбинация первых двух.
Предпосылки. Данные независимы и распределены по нормальному закону. Гипотеза о равенстве дисперсий двух нормальных генеральных совокупностей принимается, если отношение большей дисперсии к меньшей меньше критического значения распределения Фишера.
F P = S 1 2 /S 2 2
Примечание. При описываемом способе проверки значение Fpaсч обязательно должно быть больше единицы. Критерий чувствителен к нарушению предположения о нормальности.
Для двухсторонней альтернативы S 1 2 ≠S 2 2 нулевая гипотеза принимается при выполнении условия:
F l - α /2 < Fрасч < F α /2
Пример
Комплексным теплометрическим методом определяли теплофизические. характеристики (ТФХ) зеленого солода. Для приготовления образцов брали воздушно-сухой (средняя влажность W=19%) и влажный солод четырехсуточного ращения (W=45%) в соответствии новой технологией приготовления карамельного солода. Опыты показали, что теплопроводность λ влажного солода примерно в 2,5 раза больше, чем сухого, а объемная теплоемкость не имеет четкой зависимости от влажности солода. Поэтому с помощью F-критерия проверили возможность обобщить данные по средним значениям без учета влажности
Расчетные данные сведены в таблицу 5.1
Таблица 5.1
Данные к расчету F-критерия
Большее значение дисперсии получено для W=45%, т.е. S 2 45 = S 1 2 , S 2 19 = S 2 2 , и F P = S 1 2 /S 2 2 =1,35. Из таблицы 5.2 для степени свободы f 1 =N 1 -1=5 f 2 =N 2 -1=4 при γ=0,95 определяем F КР =6,2. Нуль гипотеза сформулированная как «В диапазоне влажности зеленого солода от 19 до 45% ее влиянием на объемную теплоемкость можно пренебречь» или «S 2 45 = S 2 19 » с доверительной вероятностью 95% подтвердилась, поскольку Fp Пример проверки гипотезы о принадлежности двух дисперсий одной генеральной совокупности по критерию Фишера с помощью Excel
Приведены данные по двум независимым выборкам (табл. 5.2) степени водопоглощения зерна пшеницы Было проведено исследование воздействия магнитными полями низкой частоты. Таблица 5.2 Результаты исследований Прежде, чем мы будем проверять гипотезу о равенстве средних этих выборок, необходимо проверить гипотезу о равенстве дисперсий, чтобы знать какой из критериев выбрать для ее проверки. На рис. 5.1 приведен пример проверки гипотезы о принадлежности двух дисперсий одной генеральной совокупности по критерию Фишера используя программный продукт Microsoft Excel. Рисунок 5.1 Пример проверки принадлежности двух дисперсий одной генеральной совокупности по критерию Фишера Исходные данные размещены в ячейках, находящихся на пересечении столбцов С и D со строками 3-10. Выполним следующие действия. 1. Определим, можно ли считать закон распределения первой и второй выборок нормальным (столбцы С и D соответственно). Если нет (хотя бы для одной выборки), то необходимо использовать непараметрический критерий, если да – продолжаем. 2. Рассчитаем дисперсии для первого и второго столбца. Для этого в ячейках СП и D11 поместим функции =ДИСП(СЗ:С10) и =ДИСП(DЗ:D10) соответственно. Результатом работы этих функций является рассчитанное значение дисперсии для каждого столбца соответственно. 3. Находим расчетное значение для критерия Фишера. Для этого нужно большую дисперсию разделить на меньшую. В ячейку F13 помещаем формулу =C11/D11, которая и выполняет эту операцию. 4. Определяем, можно ли принять гипотезу о равенстве дисперсий. Существует два способа, которые представлены в примере. По первому способу, задавшись уровнем значимости, например 0,05, вычисляют критическое значение распределения Фишера для этого значения и соответствующего числа степеней свободы. В ячейку F14 вводится функция =FPACПOBP(0,05;7;7) (где 0,05 - заданный уровень значимости; 7 - число степеней свободы числителя, а 7 (второе) - число степеней свободы знаменателя). Число степеней свободы равно числу экспериментов минус единица. Результат - 3,787051. Поскольку это значение больше расчетного 1,81144, мы должны принять нулевую гипотезу о равенстве дисперсий. По второму варианту рассчитывают для полученного расчетного значения критерия Фишера соответствующую вероятность. Для этого в ячейку F15 вводится функция =FPACП(F13;7;7). Поскольку полученное значение 0,22566 больше, чем 0,05, то принимается гипотеза о равенстве дисперсий. Это может быть выполнено специальной функцией. Выберите в меню последовательно пункты Сервис
, Анализ данных
. Появится окно следующего вида (рис. 5.2). Рисунок 5.2 Окно выбора метода обработки В этом окне выбираете «Двухвыборочный F-mecm для дисперсий
». В результате появится окно вида, показанного на рис. 5.3. Здесь задаются интервалы (номера ячеек) первой и второй переменной, уровень значимости (альфа) и место, где будет находится результат. Задавайте все необходимые параметры и нажимайте ОК. Результат работы приведен на рис. 5.4 Следует отметить, что функция проверяет односторонний критерий и делает это правильно. Для случая, когда критериальное значение больше 1, вычисляется верхнее критическое значение. Рисунок 5.3 Окно задания параметров Когда критериальное значение меньше 1, то вычисляется нижнее критическое. Напоминаем, что гипотеза о равенстве дисперсий отвергается, если критериальное значение больше врехнего критического или меньше нижнего. Рисунок 5.4 Проверка равенства дисперсий Номер
Номер выборки
опыта
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075