Програма для перетворення на ворд зі сканера. Сканування та розпізнавання тексту
Програми розпізнавання тексту дозволяють конвертувати сфотографовані або відскановані документи безпосередньо в пропозиції.
Справа в тому, що текст на зображенні представлений у вигляді растру, набору крапок.
Згаданий софт здійснює перетворення набору точок на повноцінний текст, доступний для редагування та збереження.
Розпізнавання букв покликане оптимізувати процес оцифрування паперових друкованих чи рукописних книг, документів.
Такий метод оцифровки на порядки перевищує швидкість ручного набору із зображення. Широко застосовується при оцифруванні бібліотек та архівів.
ABBYY FineReader 10
FineReader є беззаперечним лідером серед усіх програм, що розпізнають текст на зображенні. Зокрема, софту, який чіткіше обробляє кирилицю немає.
Взагалі в активі FineReader 179 мов, текст якими розпізнається надзвичайно успішно.
Єдина обставина, яка може розчарувати користувачів, полягає в тому, що програма є платною.
Безкоштовно поширюється лише пробна версія на 15 днів. За цей період дозволено сканування 50 сторінок.
Джерело при цьому зовсім не важливе. Будь то фотографія, скан сторінки або будь-яка картинка з літерами.
Переваги:
- точне розпізнавання;
- безліч мов читання;
- толерантність до якості зображення-джерела.
Недолік:
- пробна версія на 15 днів.
OCR CuneiForm

Безкоштовна програма для читання текстової інформації з зображень. Точність розпізнавання набагато нижче, ніж у попередньої аналізованої програми.
Але як для безкоштовної утиліти, функціонал таки на висоті.
Програма може прочитати та зберігати шрифт та кегль тексту, що розпізнається. У базі міститься більшість друкованих шрифтів.
Підтримується навіть розпізнавання тексту друкованої машинки.
Для забезпечення точності до процесу розпізнавання підключаються спеціальні словники, які поповнюють словниковий запас із документів, що скануються.
Переваги:
- безкоштовне розповсюдження;
- використання словників для перевірки правильності тексту;
- сканування тексту з ксерокопії поганої якості.
Недоліки:
- відносно невелика точність;
- невелика кількість мов, що підтримуються.
WinScan2PDF

Це навіть не повноцінна програма, а утиліта. Установка не знадобиться, а виконавчий файл важить всього кілька кілобайт.
Процес розпізнавання відбувається дуже швидко, щоправда, отримані в його результаті документи зберігаються виключно у форматі PDF.
Фактично весь процес виконується при натисканні трьох кнопок: вибір джерела, призначення та, власне, запуску програми.
Утиліта призначена для швидкої пакетної обробки множини файлів. Для зручності користувачів передбачено великий мовний пакет інтерфейсу.
Переваги:
- портативність;
- швидка робота;
- простота у використанні.
Недоліки:
- мінімальний розмір;
- єдиний формат файлів на виході.
SimpleOCR

Відмінна невелика програма для розпізнавання текстів із зображень. Підтримує навіть читання рукописів.
Біда в тому, що російська не входить ні в мовний пакет інтерфейсу, ні до списку мов, що підтримуються для розпізнавання.
Однак якщо необхідно відсканувати англійську, датську чи французьку, то кращого безкоштовного варіанту не знайти.
У своїй області програма забезпечує точну розшифровку шрифтів, видалення шуму та вилучення графічних зображень.
До того ж в інтерфейс програми вбудований практично ідентичний WordPad, що значно підвищує зручність використання програми.
Переваги:
- точне розпізнавання тексту;
- зручний текстовий редактор;
- видалення шуму із зображення.
Недоліки:
Крім того, передбачена функція багатосторінкового розпізнавання.
Поширюється Freemore OCR безкоштовно, однак, інтерфейс лише англійською.
Але ця обставина ніяк не впливає на зручність користування, тому що організовані елементи керування інтуїтивно зрозумілим чином.
Переваги:
- безкоштовне розповсюдження;
- можливість роботи з кількома сканерами;
- гідна точність розпізнавання.
Недоліки
- Відсутність російської в інтерфейсі;
- Необхідно завантажити російський мовний пакет для розпізнавання.
Програма розпізнавання тексту. Як розпізнати текст з картинки
5 безкоштовних програм для сканування та розпізнавання тексту
Напевно, кожному знайома ситуація, коли скан документа, наприклад, сторінки книги, необхідно перетворити на друкований текст. Для цього існують спеціальні програми, але основна їхня маса дуже мало кому відома. На слуху у всіх, мабуть, лише ABBYY FineReader. Справді, FineReader поза конкуренцією. Це найкраща програма для сканування та розпізнавання тексту російською мовою, проте випускається вона виключно у платних версіях і коштує дуже недешево. Чи багато хто готовий викласти за бюджетну ліцензію майже 7 000 рублів, якщо збираються обробляти одну-дві книги на рік?
Якщо ви вважаєте купівлю дорогого комерційного продукту невиправданою, чому б не скористатися аналогами, серед яких є безкоштовні? Так, вони не такі багаті функціями, але з багатьма завданнями, які, як багато хто вважає, «по зубах» тільки FineReader, справляються цілком успішно. Тож давайте познайомимося з декількома доступними альтернативами. І заразом подивимося, чим вони відрізняються від загальновизнаного зразка.
Щоб порівнювати інші програми з ABBYY FineReader, з'ясуємо, чим він такий гарний. Ось перелік його основних функцій:
- Робота з фотографіями, сканами та паперовими документами.
- Редагування вмісту файлів pdf - тексту, окремих блоків, інтерактивних елементів та іншого.
- Конвертація pdf у формат Microsoft Word та назад. Створення PDF-файлів з будь-яких текстових документів.
- Порівняння вмісту документів 35 мовами, наприклад, відсканованої паперової та електронної (не у всіх редакціях).
- Розпізнавання та перетворення сканованих текстів, таблиць, математичних формул.
- Автоматичне виконання рутинних операцій (у всіх редакціях).
- Підтримка 192 національних абеток.
- Перевірка орфографії розпізнаного тексту російською, українською та ще 46 мовами.
- Підтримка 10 графічних та 10 текстових форматів вхідних файлів, за винятком pdf.
- Збереження файлів у графічному та текстовому форматах, а також у вигляді електронних книг EPUB та FB2.
- Читання штрих-кодів.
- Інтерфейс 20 мовами, включаючи російську та українську.
- Підтримка більшості існуючих моделей сканерів.

Можливості програми чудові, але для домашніх користувачів, які не обробляють документи у промислових обсягах, є надмірними. Втім, тим, кому потрібно розпізнати лише кілька сторінок, компанія ABBYY надає послуги безкоштовно через веб-сервіс FineReaderOnline . Після реєстрації доступна обробка 10 сторінок відсканованого або сфотографованого тексту, надалі – по 5 сторінок на місяць. Більше – за доплату.
Вартість найдешевшої ліцензії FineReader для установки на комп'ютер - 6990 рублів (версія Standard).
Крихітна і вкрай проста безкоштовна утилітка, звичайно, не в змозі конкурувати з монстром, але основне завдання розпізнавання сканованого тексту, вирішує як належить. Причому для цього вона не потребує навіть встановлення на ПК (портабельна). І керується лише трьома кнопками.

Для розпізнавання тексту за допомогою WinScan2PDF натисніть «Вибрати джерело» та вкажіть підключений сканер (з готовими файлами програма, на жаль, не працює). Помістіть документ у сканер і натисніть «Сканувати». Якщо потрібно скасувати операцію, натисніть «Скасувати». Ось і вся інструкція.
Утиліта підтримує 23 мови, включаючи російську, та працює з багатосторінковими файлами. Готовий результат зберігається у форматі pdf, скан документа – у jpg.
Веб-сервіс Free-OCR.com
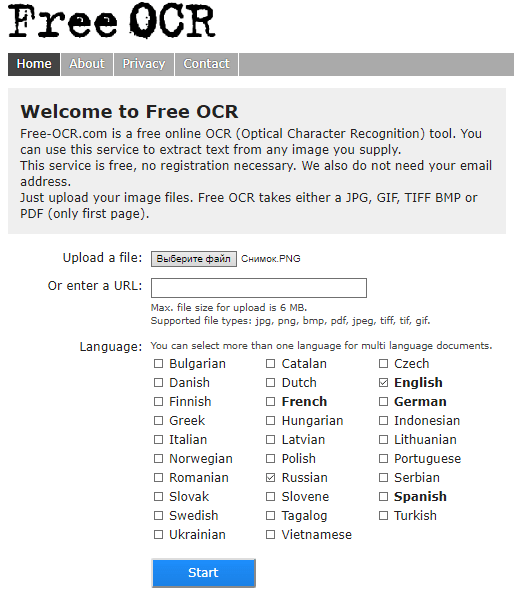
Free-OCR.com (OCR – Optical character recognition, оптичне розпізнавання символів) – безкоштовний Інтернет-сервіс для розпізнавання відсканованих або сфотографованих текстів, збережених у форматі графічного зображення (jpg, gif, tiff, bmp) або PDF. Підтримує 29 мов, включаючи російську та українську, причому користувач може вибрати не одну, а кілька, якщо їх містить вихідний текст.
Free-OCR не вимагає реєстрації та не має жодних обмежень щодо кількості завантажених документів. Обмежується лише розмір файлу – до 6 Mb. Багатосторінкові документи сервіс не обробляє, точніше, ігнорує все, окрім першого аркуша.
Швидкість розпізнавання тексту досить висока. Аркуш А4 з фрагментом книги російською мовою був оброблений приблизно за 5 секунд, але якість не порадувала. Великі шрифти – як у дитячих книжках, він розпізнає на 100%, а середні та дрібні – приблизно на 80%. З англомовними документами справи трохи кращі — дрібний і неконтрастний шрифт розпізнався правильно приблизно на 95%.
Веб-сервіс Free Online OCR

ще один безкоштовний веб-сервіс, дуже схожий на попередній, але з розширеним функціоналом. Він:
- Підтримує 106 мов.
- Обробляє багатосторінкові документи, у тому числі кількома мовами.
- Розпізнає тексти на сканах та фотодокументах безлічі типів. Окрім 10 форматів графічних зображень, обробляє документи pdf, djvu, doxc, odt, архіви zip та стислі файли Unix.
- Зберігає вихідні файли в одному з трьох форматів: txt, doc та pdf.
- Підтримує розпізнавання математичних рівнянь.
- Дозволяє повернути зображення на 90-180 ° по обидва боки.
- Правильно розпізнає текст у кількох шпальтах на одній сторінці.
- Може розпізнати один вибраний фрагмент.
- Після обробки пропонує скопіювати файл до буфера обміну, завантажити на комп'ютер, завантажити на сервіс Google Docs або опублікувати в Інтернеті. Також можна відразу перекласти текст іншою мовою, використовуючи Google Translate або Bing Translator.
Потрібно віддати належне Free Online OCR і за те, що він непогано читає картинки низького дозволу та малої контрастності. Результат розпізнавання всіх згодом йому російськомовних текстів відмовився стовідсотковим чи близьким до цього.
Free Online OCR, на нашу думку, одна з найкращих альтернатив FineReader, але безкоштовно він обробляє лише 20 сторінок (щоправда, не вказано, за який період). Подальше використання сервісу коштує від $0,5 за сторінку.
Microsoft OneNote
Програма для створення нотаток Microsoft OneNote, крім дуже старих і останньої — 17 версії, також містить функціонал OCR. Він не такий просунутий як у спеціалізованих додатках, але також придатний для використання, якщо немає інших варіантів.
Щоб розпізнати текст із зображення за допомогою OneNote, вставте зображення у файл («Малюнок» — «Вставити»), натисніть на нього правою клавішею мишки та виберіть «Копіювати текст із малюнка».

Після цього вставте скопійований текст у будь-яке місце нотатки.
За умовчанням мовою розпізнавання призначено англійську. Якщо вам потрібна російська або якась інша, змініть налаштування вручну.
Якість розпізнавання російськомовного тексту Microsoft OneNote залишає бажати кращого, тому його не можна назвати повноцінною заміною FineReader. Та й обробляти у ньому великі багатосторінкові документи дуже незручно.
SimpleOCR

Старенька безкоштовна програма SimpleOCR - теж дуже гідний інструмент розпізнавання текстів з електронних зображень та сканів, але, на жаль, без підтримки російської мови. Натомість у ній є унікальна функція зчитування рукописних слів, а також редактор, що дозволяє виправити помилки перед збереженням готового результату.
Інші можливості SimpleOCR:
- Перевірка орфографії із можливістю поповнювати словник вручну.
- Читання документів у низькій роздільній здатності та з помарками (є опція очищення «шуму»).
- Максимально близька добірка шрифту та передача стилів написання (жирний, курсив). За бажанням функцію можна вимкнути.
- Одночасна обробка кількох аркушів чи окремого фрагмента.
- Виділення можливих помилок у готовому тексті для ручного редагування.
- Підтримка багатьох модифікацій сканерів.
- Вхідні формати електронних документів: tif, jpg, bmp, ink та скани.
- Збереження готового тексту у форматах txt та doc.
Якість розпізнавання і друкованих текстів, і рукописів є досить високою.
Програму можна було б назвати універсальною, якби не обмеження мовної підтримки. Остання версія підтримує лише англійську, французьку та данську мови, додавання інших, швидше за все, не планується. Інтерфейс повністю англійською, але простий для розуміння. Крім того, в головному вікні є кнопка "Demo", яка запускає навчальний ролик по роботі з SimpleOCR.

Програма бельгійської компанії-розробника I.R.I.S — ось це справді справжній конкурент російському ABBYY FineReader. Потужна, швидка, кросплатформова, заснована на фірмовому OCR-движку, використовуваному виробниками Adobe, HP і Canon, вона чудово розпізнає навіть тексти, які важко читати. Підтримує 137 мов, серед яких є російська та українська.
Особливості та функції Readiris:
- Найвища швидкість обробки файлів серед додатків такого класу розрахована на великі обсяги.
- Збереження форматування вихідного тексту (шрифти, кегль, стиль написання).
- Одиночна та пакетна обробка файлів, підтримка багатосторінкових документів.
- Розпізнавання математичних рівнянь, спеціальних символів та штрих-кодів.
- Очищення тексту від "шумів" - ліній, помарок тощо.
- Інтеграція з різними хмарними сервісами - Google Документи, Evernote, Dropbox, SharePoint та іншими.
- Підтримка сучасних моделей сканерів.
- Формати вхідних даних: pdf, djvu, jpg, png та інші, у яких зберігають графічні зображення, а також отримане безпосередньо зі сканера.
- Формати вихідних даних: doc, docx, xls, xlsx, txt, rtf, html, csv, pdf. Підтримується конвертація у djvu.
Інтерфейс програми російськомовний, використання інтуїтивно зрозуміле. Вона не надає користувачам можливості редагувати вміст pdf-файлів, як FineReader, але з головним завданням - розпізнаванням текстів, на наш погляд, справляється відмінно.
Readiris випускається у двох платних версіях. Вартість ліцензії Pro складає 99,00 €, Corporate - 199 €. Майже як у ABBYY.
Freemore OCR

Freemore OCR - (! сайт програми http://freemoresoft.com/freeocr/index.phpможе блокуватися антивірусами через вбудований в установник рекламного «сміття») — ще одна проста, компактна та безкоштовна утилітка, яка теж непогано розпізнає тексти, але за умовчанням лише англійською. Пакети інших мов потрібно завантажувати та встановлювати окремо.
Інші функції та можливості Freemore OCR:
- Одночасна робота з кількома сканерами.
- Підтримка багатьох форматів графічних даних, у тому числі пропрієтарних, на кшталт psd (файл Adobe Photoshop). Стандартні формати графіки підтримуються усі.
- Підтримка PDF.
- Збереження готового результату у форматі pdf, txt або docx, причому для експорту тексту Word достатньо натиснути одну кнопку на панелі інструментів.
- Вбудований редактор (на жаль, форматування вихідного документа програма не зберігає).
- Перегляд властивостей документа.
- Друк розпізнаного тексту прямо із головного вікна.
- Захист паролем файлів у форматі PDF.
На перший погляд, інтерфейс програми може здатися складним, але насправді користуватися нею дуже легко. Інструменти поділені на групи, як на стрічці Microsoft Office. Якщо розглянути їх уважніше, призначення тієї чи іншої кнопки стане зрозумілим.
Щоб завантажити електронний документ у вікно Freemore OCR, спочатку виберемо його тип - зображення або файл pdf, а потім натиснемо відповідну кнопку "Load". Щоб розпочати процес розпізнавання, натискаємо кнопку «OCR» в однойменній групі інструментів поруч із зображенням чарівної палички (показана на скріншоті).
Результат сканування англомовних текстів як із добре-, так і з поганочитаної картинки виявився цілком задовільним. Не сподобалося лише одне — те, що разом із програмою на комп'ютер встановлюється сміття — якісь липові антивірусні сканери, оптимізатори та інші непотрібні речі, причому без можливості відмовитися від них під час встановлення. Словом, якби не цей недолік, програму можна було б рекомендувати як непогану безкоштовну альтернативу FineReader.
Добридень.
Напевно, кожен із нас стикався із завданням, коли потрібно перевести паперовий документ в електронний вигляд. Особливо це часто потрібно робити тим, хто навчається, працює з документацією, перекладає тексти за допомогою електронних словників тощо.
Не всі одразу розуміють одну річ. Після сканування (пригону всіх аркушів на сканері) у вас будуть зображення формату BMP, JPG, PNG, GIF (можуть бути й інші формати). Так ось з цієї картинки потрібно отримати текст – ця процедура називається розпізнаванням. У такому порядку і буде виклад нижче.
1. Що потрібно для сканування та розпізнавання?
1) Сканер
Для перекладу друкованих документів у текстовий вигляд, вам спочатку потрібен сканер і, відповідно, «рідні» програми та драйвери, які з ним йшли. За допомогою них можна буде сканувати документ та зберегти його для подальшої обробки.
Можна скористатися й іншими аналогами, але софт, який йшов зі сканером у комплекті, зазвичай працює швидше та має більше опцій.
Залежно від того, який у вас сканер – швидкість роботи може суттєво відрізнятися. Є сканери, які можуть отримати картинку з аркуша за 10 сек., які отримуватимуть за 30 сек. Якщо скануєте книгу на 200-300 аркушів - думаю, не важко підрахувати, скільки разів буде різниця в часі?
2) Програма для розпізнавання
У нашій статті я показуватиму вам роботу в одній з найкращих програм для сканування та розпізнавання будь-яких документів - ABBYY FineReader. Т.к. програма платна, то відразу дам посилання і на іншу – її безкоштовний аналог. Правда, я б не став їх порівнювати, через те, що FineReader виграє за всіма параметрами, рекомендую все ж таки спробувати саме її.
ABBYY FineReader 11
Одна з найкращих програм у своєму роді. Вона призначена для того, щоб розпізнати текст на зображенні. Вбудовано безліч опцій та функцій. Може розібрати купу шрифтів, підтримує навіть рукописні варіанти (щоправда, особисто не пробував, думаю, добре навряд чи розпізнаватиме рукописний варіант, якщо тільки у вас не ідеальний каліграфічний почерк). Докладніше про роботу з нею буде розказано нижче. Тут же зауважимо, що у статті буде розказано про роботу у програмі 11 версії.
Як правило, різні версії ABBYY FineReader не дуже відрізняються одна від одної. Ви легко зробите те саме і в іншій. Головні відмінності можуть бути у зручності, швидкості роботи програми та її можливостях. Наприклад, попередні версії відмовляються відкривати PDF і DJVU документи.
3) Документи для сканування
Так, ось так ось, вирішив винести документи окремою графою. Найчастіше сканують якісь підручники, газети, статті, журнали та інших. тобто. ті книги та ту літературу, яка користується попитом. Я це до чого веду? З особистого досвіду можу сказати, що багато чого ви захочете сканувати - можливо вже є в мережі! Скільки разів особисто я економив час, коли знаходив ту чи іншу книгу, вже скановану в мережі. Мені залишалося лише скопіювати текст у документ та продовжити з ним роботу.
З цього проста порада - перш ніж щось сканувати, перевірте, чи може вже хтось відсканував і вам не потрібно втрачати свій час.
2. Параметри сканування тексту
Тут я не розповідатиму про ваші драйвери для сканера, програми, які разом з ним йшли, бо всі моделі сканерів різні, ПЗ теж скрізь різне і вгадати і тим більше показати наочно як виконувати операцію - нереально.
Але у всіх сканерах є одні й ті ж налаштування, які можуть вплинути на швидкість і якість вашої роботи. Ось про них якраз і поговоримо тут. Перераховуватиму по порядку.
1) Якість сканування – DPI
По-перше, якість сканування поставте в опціях не нижче 300 DPI. Бажано навіть виставити більше, якщо це можливо. Чим вище показник DPI - тим чіткіше вийде ваша картинка, та й тим самим, швидше пройде подальша обробка. До того ж чим вище якість сканування - тим менше помилок вам доведеться виправляти.
Оптимальний варіант забезпечує, як правило, 300-400 DPI.
2) Кольоровість
Цей параметр дуже сильно впливає на час сканування (до речі, DPI теж впливає, але ті так сильно, і коли користувач ставить високі значення).
Зазвичай виділяють три режими:
Чорно-білий (відмінно підійде для простого тексту);
Сірий (підійде для тексту з таблицями та картинками);
Кольоровий (для кольорових журналів, книг, загалом документів, де важлива кольоровість).
Зазвичай від вибору кольору залежить час сканування. Адже якщо документ у вас великий, то навіть зайві 5-10 секунд на сторінці загалом виллються в пристойний час.
3) Фотографії
Документ ви можете отримати не лише скануванням, а й сфотографувавши його. Як правило, у цьому випадку у вас будуть деякі інші проблеми: спотворення картинки, змазаність. Через це може знадобитися більш тривале подальше виправлення та обробка отриманого тексту. Особисто я не рекомендую користуватися фотоапаратами для цієї справи.
Важливо, що кожен такий документ вдасться розпізнати, т.к. якість сканування у нього може бути вкрай низькою.
3. Розпізнавання тексту документа
Після відкриття в ABBYY FineReader картинки, програма, як правило, на автоматі починає виділяти області та розпізнавати їх. Але іноді вона робить це неправильно. Для цього ми і розглянемо виділення потрібних областей вручну.
Важливо! Не всі відразу розуміють, що після відкриття документа в програмі, зліва у вікні відображається вихідний документ, в якому ви виділяєте різні області. Після натискання на кнопку розпізнавання програма у вікні праворуч виведе вам готовий текст. Після розпізнавання, до речі, доцільно перевірити текст на помилки у тому самому FineReader.
3.1 Текст
Ця область використовується для виділення тексту. Картинки та таблиці потрібно виключати з неї. Рідкісні та незвичайні шрифти доведеться вводити вручну.
Для виділення текстової області зверніть увагу на панель у верхній частині FineReader. Там є кнопка "Т" (див. скріншот нижче, покажчик мишки якраз на цій кнопці). Клацаєте по ній, потім на малюнку нижче виділяєте акуратно прямокутну область, в якій міститься текст. До речі, у деяких випадках потрібно створювати текстових блоків по 2-3, інколи ж по 10-12 на сторінку, т.к. форматування тексту може бути різним і одним прямокутником всю область не виділити.
Важливо, що у текстову область не повинні потрапляти картинки! Надалі це вам заощадить купу часу.
3.2 Зображення
Використовується для виділення картинок і тих областей, які важко розпізнати через погану якість або незвичайність шрифту.
На скріншоті нижче покажчик мишки знаходиться на кнопці, яка використовується для виділення області "картинка". До речі, в цю область можна виділити будь-яку частину сторінки, а FineReader вставить її потім в документ як звичайну картинку. Тобто. просто «тупо» скопіює…
Зазвичай цю область використовують для виділення погано відсканованих таблиць, для виділення нестандартного тексту і шрифту, картинок.
3.3 Таблиці
На скріншоті нижче показана кнопка виділення таблиць. Взагалі особисто я її використовую вкрай рідко. Справа в тому, що вам доведеться досить рутинно малювати (фактично) кожну лінію на таблиці і показувати, що і як програмі. Якщо таблиця невелика і в не дуже хорошій якості, я рекомендую для цього використовувати область «картинка». Тим самим заощадите купу часу, а таблицю можна потім у Word зробити швиденько на основі картинки.
3.4 Непотрібні елементи
Важливо відмітити. Іноді на сторінці є непотрібні елементи, які заважають розпізнати текст або взагалі не дають вам виділити потрібну область. Їх можна за допомогою «ластика» видалити зовсім.
Для цього переходимо до режиму редагування зображення.
Вибираємо інструмент «гумка» і виділяємо непотрібну область. Вона зітреться і на її місці буде білий аркуш паперу.
До речі, рекомендую використовувати вам цю опцію якнайчастіше. Намагайтеся всі текстові області, які ви виділили, де вам не потрібен шматок тексту, або присутні будь-які непотрібні точки, розмитості, спотворення - видаляти гумкою. Завдяки цьому розпізнавання буде швидшим!
4. Розпізнавання файлів PDF/DJVU
Взагалі, цей формат розпізнавання нічого очікувати відрізнятиметься нічим іншим від інших - тобто. працювати з ним можна так само як із картинками. Єдина програма не повинна бути занадто старою версією, якщо файли PDF/DJVU у вас не відкриваються - оновіть версію до 11.
Невелика порада. Після відкриття документа у FineReader – він автоматично почне розпізнавати документ. Часто у файлах PDF/DJVU певна область сторінки не потрібна у всьому документі! Щоб видалити таку область на всіх сторінках, зробіть таке:
1. Зайдіть до розділу редагування зображення.
2. Увімкніть опцію «обрізання».
3. Виділіть область, потрібну вам на всіх сторінках.
4. Натисніть застосувати до всіх сторінок та обріжте.
5. Перевірка помилок та збереження результатів роботи
Здавалося б, які ще можуть бути проблеми, коли всі області були виділені, потім розпізнані - бери та зберігай… Не тут було!
По-перше, потрібна перевірка документа!
Щоб її увімкнути, після розпізнавання, у вікні праворуч буде кнопка «перевірка», див. скріншот нижче. Після її натискання програма FineReader автоматично показуватиме вам ті області, де у програми виникли помилки і вона не змогла достовірно визначити той чи інший символ. Вам залишиться тільки вибирати, або ви погоджуєтесь з думкою програми, або вводите свій символ.
До речі, в половині випадків, наприклад, програма вам пропонуватиме готове правильне слово - вам залишиться тільки мишкою вибрати потрібний варіант.

По-друге, після перевірки потрібно вибрати формат, в який ви збережете результат своєї роботи.
Тут FineReader дає вам розвернутися на повну котушку: можна просто передати інформацію в Word один на один, а можна зберегти її в одному з десятків форматів. Але хотілося б виділити інший важливий аспект. Який формат не вибрали б, важливіше вибрати тип копії! Розглянемо найцікавіші варіанти…
Точна копія
Усі області, які ви виділяли на сторінці в розпізнаному документі, будуть відповідати точнісінько вихідному документу. Дуже зручний варіант, коли вам важливо не втратити форматування тексту. До речі, шрифти також будуть дуже схожі на оригінал. Рекомендую при такому варіанті передавати документ у Word, щоб там продовжити подальшу роботу.
Редагована копія
Цей варіант хороший тим, що ви отримаєте форматований варіант тексту. Тобто. відступів із «кілометр», які можливо були у вихідному документі – ви не зустрінете. Корисна опція, коли ви значно редагуватимете інформацію.
Щоправда, не варто вибирати, якщо вам важливо зберегти стилістику оформлення, шрифти, відступи. Іноді, якщо розпізнавання пройшло не дуже успішно – ваш документ може «перекосити» через змінене форматування. І тут доцільно вибрати точну копію.
Простий текст
Варіант для тих, кому потрібен просто текст зі сторінки без іншого. Підійде для документів без картинок та таблиць.
На цьому стаття зі сканування та розпізнавання документа добігла кінця. Сподіваюся, що за допомогою цих простих порад ви зможете вирішити свої завдання.
Розпізнавання тексту дуже зручна можливість. Вам більше не потрібно передруковувати великі обсяги з книг та статей. Для вчителів, студентів та науковців такі програмні програми – справжній подарунок. Розглянемо різні програми та визначимо, яка програма для розпізнавання тексту з картинки – найкраща.
Як це працює
Оптичне розпізнавання тексту (OCR – Optical Character Recognition) – це можливість перетворити текст із графічного вигляду (фото, скан, pdf) у звичайний формат. Перетворений текст можна редагувати.
Будь-яка растрова картинка складається з крапок. Програмне забезпечення для розпізнавання виділяє на малюнку літери та перекладає їх у текст. Відбувається аналіз структури документа. Виділяються текстові блоки. Потім будуються лінії, які поділяються на слова, а потім символи. Кожен символ порівнюється із шаблонами. Після чого будуються гіпотези, що це символ. Виходячи з них, ПЗ аналізує різні варіанти розбиття рядків на слова, а слова на символи. Кількість таких гіпотез величезна. Зрештою програма приймає рішення та видає текст.
Огляд програмного забезпечення
Умовно всі програми можна розділити на три категорії:
- Платні.
- Безкоштовні.
- Онлайн-сервіси.
Розглянемо кілька варіантів із кожного розділу.
Платні та безкоштовні програми
OCR CuneiForm
Безкоштовна програма для розпізнавання тексту, який можна скачати тут.
Програма була розроблена в 1993 році в компанії Cognitive Technologies. Однією з головних особливостей її на той момент була можливість розпізнавання суміші російської та англійської мов. У 2009 році була додана гілка, яка дозволяє розпізнавати суміш інших мов. Програмний продукт поставлявся зі сканерами та БФП від провідних виробників: Hewlet-Pachard, Epson, Xerox і т.д. Остання версія вийшла у 2009 році.
Після скачування та встановлення пробуємо розпізнати текст. Наприклад візьмемо цю статтю.
Інтерфейс програми простий, меню російською. 
Натискаємо значок папки та вантажимо картинку. Натискаємо кнопку розпізнавання. 
Результат не вражає. Різнокольоровий текст не розпізнано. 
Незважаючи на заявлене використання різних словників, англійська теж розпізналася погано. 
Загалом, ідеальне фото можна перевести в символи, але що нижча якість вихідної картинки, то нижча вона і в результату.
Слід зазначити, що це єдина русифікована програма розпізнавання тексту під час сканування, яку вдалося завантажити безкоштовно легально. Решта в кращому випадку має пробний безкоштовний період.
RiDoc
Програма для розпізнавання тексту з фото або сканера з безкоштовним періодом 30 днів. Завантажити можна тут.
Додаток має непоганий функціонал і доступний інтерфейс. Для завантаження зображення натискаємо кнопку «Відкрити». 
Далі кнопку "Розпізнати". 
У результаті одержуємо готовий результат. Його можна відкрити у Word чи OpenOffice. 
Ось результат. 
Теж не ідеально, але набагато більше, ніж у попередньому випадку.
Також можна накласти водяний знак або склеїти кілька картинок.
ReadIris
Платний програмний продукт із пробною версією, розрахованою на 100 сторінок або 10 днів. Завантажити програму для сканера для розпізнавання тексту з офіційного сайту можна тут.
Розробник – бельгійська компанія IRIS, створена 1986 року. Основна спеціалізація – технології та продукти для інтелектуального розпізнавання документів.
Програма перетворює картинку, PDF-файл або відсканований документ у текстовий файл, що повністю редагується. Виймає текст із документів, зберігаючи при цьому макет вихідного файлу. Має такі можливості:
- конвертувати файли Word, Excel та PowerPoint у індексовані PDF-файли;
- конвертація документів за допомогою контекстного меню;
- індикатор якості для документів, що імпортуються;
- автоматичне виявлення сканерів;
- модуль корекції перспективи
Інтерфейс програми русифікований (вказується при встановленні) і досить простий. 
Натискаємо кнопку «З файлу» та вибираємо нашу картинку. Програма автоматично розділила її на два блоки. 
Щоб розпізнати, натисніть кнопку «Відкрити» та вкажіть шлях для зображення. Формат вказується рядком вище. 
Результат перевершив усі очікування. Навіть зображення збереглося. 
Можна надіслати документ поштою або хмарою. Для цього слід клацнути по списку зверху та вибрати. За промовчанням зберігається у файлі. 
Коштує ця програма близько 6000 руб.
ABBYY FineReader
Найвідоміша та найрозкрученіша програма. Завантажити пробну версію можна тут.
Платна коштує 6990 грн. Російська розробка 1993 року, досі вважається однією з найкращих у світі. Основні можливості:
- Розпізнавання таблиць та графіків, математичних формул.
- Перегляд та навігація pdf.
- Створення та пряме редагування pdf.
- Робота з цифровим підписом.
- Порівняння документів.
- Додавання коментарів.
Програма має безліч можливостей. Інтерфейс русифікований та доступний. 
Після натискання кнопки «Відкрити» та вибору картинки, починається автоматичний його поділ на блоки. 
Для початку процесу натисніть на відповідну кнопку. 
Далі залишилося вибрати, у якому форматі зберігати та вказати папку, до якої слід зберегти документ. 
Відкриємо результат. Як бачите, розпізнавання пройшло ідеально. 
Ще раз порівняємо з ReadIris. 
Перший варіант (Finereader) виконаний бездоганно. Тому, мабуть, пальму першості віддаємо цій програмі. За ціною вони можна порівняти, так що різниця в 600-700 рублів особливої ролі не відіграє.
Розпізнавання тексту по фото онлайн
IMGonline
Онлайн сервіс обробки картинок. На сайті представлені інструменти:
- Стиснення та зміна розміру картинки
- Обрізка, кадрування
- Обробка вбудованих метаданих
- Ефекти
- Поліпшення
- Визначення палітри кольорів зображення
- Отримання фону
- Визначення відсотка схожості та ін.
Зручний сайт, який дає безліч можливостей обробки картинки. Інтерфейс простий та зрозумілий. 
Пропонує дві програми. Порівняємо. Завантажимо файл та натиснемо кнопку «ОК». 
Далі натискаємо на заслання. 
Результат не тішить. 
Пробуємо другу програму. 
Теж сумнівно. 
Виставимо додаткову мову. 
Перевіряємо результат.
Трохи краще, але досконало далеко.
img2txt
Програма розпізнавання тексту з фото онлайн, сканування не допускає.
Сайт працює з 2014 року. Інших сервісів, окрім цього, розробники не планують. 
Виберіть файл та натисніть «Завантажити». Потім натисніть «Почати розпізнавання». 
Результат також далекий від досконалості. 
Сонvertio
Достатньо великий платний портал, на якому ви можете скористатися такими можливостями:
- Конвертація відео, аудіо, картинок.
- Перетворення PDF на Word, Excel, PowerPoint.
- Розділення PDF.
- Стиснення PDF, PNG та ін.
Принцип роботи абсолютно аналогічний, але налаштувань більший. Зображення можна перетягувати. 
Можна вказати кілька мов та тип документа, куди зберігається результат. 
Незареєстрованим користувачам доступно лише 10 сторінок для розпізнавання.
Після натискання на каптчу виберіть «Перетворити». 
Натисніть на скачати. 
Результат перевершив усі очікування. 
Виявляється, і прості сервіси онлайн мають можливість якісного розпізнавання. Тож Convertio оголошується однозначним переможцем у цій номінації. Але, як і будь-який чудовий продукт, він платний. 
Отже, ми розглянули різні інструменти розпізнавання тексту. З'ясувалося, що безкоштовні можуть допомогти, але якість залишається не на висоті. Отже, якщо вам постійно потрібно перекладати текст із друкованого вигляду в електронний, доведеться розщедритися.
Чудового Вам дня!
Програма для якісного розпізнавання та оцифрування тексту з картинки, фотографії або pdf-файлу знадобилася мені у студентстві. Адже передруковувати відскановані чи сфотографовані аркуші з лекціями було дуже довго та трудомістко. Я, звичайно ж, знайшла програму, яка оцифровує текст, але вибудовувати колонки, таблиці чи списки все одно доводилося вручну. З програмою ReadIris у вас не виникне такої проблеми!
Взагалі ReadIris це найпотужніша система для оптичного розпізнавання символів на даний момент. Її вже гідно оцінили як новачки в цій справі, так і досвідчені користувачі, яким доводиться стикатися з оцифруванням тексту. ReadIris може розпізнавати не тільки стандартний буквено-числовий текст, але також формули, штрих-коди та різноманітні символи. До того ж, вона дозволяє зберігати оцифрований текст у форматах HTML, DOC, RTF, CSV і TXT.
Завантажити програму для розпізнавання тексту
Завантажити програму ReadIris для розпізнавання тексту можна безкоштовно за посиланням нижче. Вона повністю сумісна з усіма найпоширенішими офісними програмами: Microsoft Office, StarOffice та OpenOffice. На даний момент цим не може похвалитися жоден подібний додаток! Інтерфейс ReadIris російською мовою простий і зрозумілий, тому від вас не потрібно ніяких додаткових знань. Після встановлення вам знадобиться лише запустити програму, відкрити в ній потрібне вам зображення тексту в будь-якому форматі і все готовий оцифрований текст вже на вашому пристрої!